Quick answer
As of Q2 2026, three AI categories run at production scale across US acute-care
hospitals — imaging triage, ambient clinical documentation, and revenue-cycle denials. Every
other widely-marketed clinical AI use case is either pilot, demo, or whitepaper. The failure mode
underneath the stalled categories is the same one that took down the Epic Sepsis Model in 2021:
site-specific distribution shift the vendor never tested for.
The Contrarian Observation that Frames the Rest of this Post
After reviewing the deployment evidence at fifty-plus US health systems and tracking the JAMA, JAMIA,
and npj Digital Medicine validation literature against vendor adoption claims, I can tell you the productionpilot wedge in hospital AI is not what conference demos suggest. It is not model accuracy. It is whether the
model actually keeps that accuracy when it leaves the training site.
The use cases that have crossed into production at Mayo Clinic, Johns Hopkins, UPMC, Northwell, Duke,
Cleveland Clinic, Mass General Brigham, Yale New Haven, Cedars-Sinai, Atrium Health, Banner Health,
Mercy, Cooper University, Novant, Memorial Sloan Kettering, Endeavor, and the rest of the named-adopter
list are not the most clinically ambitious ones. They are the ones where the input distribution is stable
enough across sites that the model does not silently degrade when it lands at hospital number two, three,
or four. The use cases still in pilot have models that score beautifully at the development site and fall apart
somewhere between site one and site five.
This post is the audit. Three categories have crossed. Everything else has not. The 3-Track Acute-Care
AI Production Bar explains why — and tells you which of your 2026 budget bets are actually fundable
today versus which ones will still be PowerPoint slides at the next HIMSS.
What "Production AI" Actually Means in a US Hospital
Most “AI in healthcare” listicles in 2026 still confuse three different things: a tool that has FDA clearance, a tool that has paying customers, and a tool that has been deployed at scale across multiple Tier-1 health systems with measurable clinical or financial outcomes attached. Only the third counts as production.
For this audit, a hospital AI use case is “in production” if it meets all four conditions:
- Three or more named Tier-1 deployments at academic medical centers, integrated delivery networks, or large not-for-profit health systems
- Use across multiple hospitals, not a single pilot site
- Measurable outcome attached — hours saved, denials reduced, accuracy verified, patient throughput improved, with a number from a non-vendor source where possible
- Integrated into the system the team already uses — Epic, Oracle Health, MEDITECH, the existing PACS, the existing RCM stack — not a standalone dashboard nobody opens
The “71% of nonfederal acute-care hospitals report using predictive AI integrated with their EHRs in 2024” headline from the AHA/ONC Information Technology Supplement is real, but that figure conflates pilots, deployments, and shadow IT. The number that matters is buried in the same survey: 86% of hospitals affiliated with multi-hospital systems report AI use, versus only 37% of independent facilities — and rural hospitals report 56% versus 81% for urban hospitals. The Bain & Company / KLAS October 2025 Healthcare IT Spending study sharpens this further: ambient documentation is the single use case furthest along, with roughly one in five providers at full rollout and two in five still in pilot. That is the production tier — narrow, named, and uneven.
The Key Takeaway: hospital AI is not failing. It is bifurcating. A small number of categories are scaling fast.
Most are not. And the regulatory and clinical floor under the stalled ones is starting to rise.
The Three Categories that Have Crossed into Production
Track 1 — AI-powered imaging triage in radiology
The most-deployed AI category in US acute care. Two vendors dominate the production tier and both have
crossed the named-adopter, multi-site, measured-outcome bar.
Aidoc runs across more than 1,500 hospitals globally including Yale New Haven and Cedars-Sinai, with
the aiOS platform analyzing more than 100 million patient cases to date. In January 2026 the FDA cleared
Aidoc’s CARE foundation model for comprehensive abdominal CT triage covering 14 acute indications in a
single workflow — 11 newly cleared, three previously cleared — with a mean sensitivity of 97% and a
mean specificity of 98% in the FDA-reviewed pivotal study. This is the first FDA clearance for a foundationmodel approach to multi-condition triage and the company says it reduced false alerts by roughly an order
of magnitude versus best-in-class single-condition tools.
Viz.ai runs across more than 1,700 hospitals worldwide with 50+ FDA-cleared algorithms across stroke,
pulmonary embolism, intracerebral hemorrhage, and cardiac imaging. Named US adopters include
Banner Health, Ohio State University Medical Center, Atrium Health, Piedmont Healthcare, Huntington
Hospital (the first in Los Angeles County), Montefiore (using Viz ICH Plus inside the Neuroemergencies
Management and Transfer program), and UK St. Claire. Viz.ai was named #1 in the 2025 Black Book
Survey of AI-Powered Acute Care and Clinical Decision Support Vendors. The use case crossed the
production bar because the AI’s output appears inside the radiologist’s PACS workflow and the
neurovascular specialist’s mobile phone — not in a separate dashboard the on-call physician will not
open.
Why imaging triage works in production: the input distribution is medical-grade and reasonably stable. CT and MR scanners produce DICOM output to specifications. The clinical question is binary or near-binary. The cost of a false positive is bounded — a radiologist verifies the flag in seconds. And the FDA 510(k) pathway has forced external validation studies that the rest of clinical AI does not consistently get.
Track 2 — Ambient clinical documentation
The fastest-growing production category in 2025–2026 and the one with the deepest enterprise-wide
commitments.
Microsoft Dragon Copilot (the unified successor to Nuance DAX Copilot and Dragon Medical One) was used to document more than 13 million patient encounters in a single quarter of Microsoft’s fiscal year 2025 — up nearly seven-fold year over year, per Satya Nadella’s July 2025 earnings remarks. Mercy in Chesterfield, Missouri now has more than 1,000 physicians on the platform with more than 100,000 hours saved to date and a plan to reach all 5,000 providers. Cooper University Health Care, Atrium Health, Novant Health, Overlake, Baptist Health, and The Ottawa Hospital are named adopters. Dragon Copilot is the first ambient solution natively integrated into the Epic EHR workflow — and that integration depth is the reason it is in production.
Abridge is now deployed at more than 200 health systems. UPMC is scaling to more than 12,000 clinicians by 2026 across 40+ hospitals and 800 outpatient sites. Northwell Health is rolling Abridge across all 28 of its hospitals as part of one of the largest Epic implementations in the country. Within the first half of 2025, enterprise-wide implementations were announced at Duke Health, Johns Hopkins Medicine, Mayo Clinic, and UNC Health. Other named adopters include Memorial Sloan Kettering, Inova, Endeavor Health, Akron Children’s, Emory Healthcare, UChicago Medicine, Highmark Health/AHN, and Oak Street Health. Abridge won Best in KLAS 2025 for Ambient AI. Linked Evidence — the company’s mechanism for mapping AI-generated summary statements back to source data — is the trust scaffolding that allowed clinicians to scale adoption past the pilot ceiling.
The KLAS Healthcare AI Update from December 2025 confirms the scale of the shift: 79% of healthcare organizations using AI have adopted ambient speech, and ambient documentation is the highest-mindshare AI category across 3,370 respondents from 1,742 unique organizations. Among Epic-using hospitals, 62.6% had adopted ambient AI by June 2025 per the recent AJMC analysis.
Why ambient documentation works in production: the operator is the clinician and the operator is also the verifier. Every note is clinician-reviewed before it lands in the chart. The cost of an AI error is bounded by that human-in-the-loop step. The integration path runs through Epic. And the ROI is unambiguous — clinicians report getting weekends back.
Track 3 — Revenue-cycle denials, coding, and prior authorization
The least-discussed production category and the one that is generating the hard-dollar ROI that hospital CFOs respond to in 2026.
AKASA is the named GenAI specialist in the production tier. Cleveland Clinic announced a strategic collaboration with AKASA to deploy GenAI tools for coding and documentation. Nebraska Methodist Health System worked with AKASA to automate claim status checks and contributed to a $30 million gross yield increase. Solventum (formerly 3M Health Care) remains the established player for autonomous coding at scale. Epic’s own Cheers and Hello AI agents for denials management and chart summarization are being rolled out across the Epic install base, which means the production category is also platform-native.
The adoption math is the most concrete in healthcare AI. Per the AHA/ONC 2025 IT Supplement, the share of hospitals using AI for billing jumped from 36% to 61% in the single year between 2023 and 2024. Scheduling AI went from 51% to 67%. The KLAS Dec 2025 report shows claims adjudication at 24% adoption, coding automation at 24%, and denials management at 17%. The AKASA/HFMA Pulse Survey reports 46% of US hospitals now deploy AI somewhere in their RCM stack, and 78% are using or implementing some form of revenue-cycle automation.
Why RCM works in production: the input distribution is structurally stable. Payer rules change but they change slowly and they are documented. Claim adjudication outcomes are labeled by the payer in real time — every claim that gets paid or denied is a self-labeling training example. The cost of an AI error is recoverable through standard appeals workflows. And the ROI is denominated in dollars, which is the only currency every hospital CFO speaks fluently.
What is still in Pilot, Demo, or Whitepaper — And Why
These are the categories the conference circuit is most excited about. They are also the ones where, if
your CMIO or hospital CEO has approved budget in 2025–2026, you are most likely staring at a
deployment with no production handoff in sight.
The Epic Sepsis Model is the
canonical case (autopsy in the next section). EHR-native risk models for in-hospital mortality, readmission
risk, and deterioration are widely deployed but rarely production-grade by the four-condition definition
above — most stall on operator trust after the first six months because alert fatigue compounds faster than
the predictive value justifies. The 2024 Harris Health study of the Epic Sepsis Predictive Model v1.0
across two Houston EDs reported a sensitivity of 14.7% and a positive predictive value of 7.6% in the sixhour onset window. That is not a production-grade outcome.
The KLAS Healthcare AI Update from December 2025 is the most consequential data point of the year on this category: of more than 3,000 respondents across 1,742 organizations, only 17 mentioned agentic AI specifically and only one organization reported current production use. Vendor marketing is at peak hype. Buyer adoption is at floor. Gartner has separately forecast that 40% of agentic AI projects will be cancelled by end of 2027 over cost, value, and risk concerns — and clinical care is the single highest-stakes deployment context in the agentic AI category.
The meta-analysis of 83 studies on diagnostic accuracy across LLMs reported overall diagnostic accuracy of 52.1% — comparable to non-expert physicians but significantly lower than expert physicians. That is an interesting research finding. It is not a production deployment.
The category is in motion. Highmark Health and Abridge announced a “real-time prior authorization at the point of conversation” collaboration. But true autonomy — submission, adjudication, response, follow-up — without a human reviewer in the loop is rare in production today.
Some of these are production-adjacent. Epic’s automated patient message responses are deployed widely. But the operator-trust threshold for clinical messaging at scale is still being earned, and the Microsoft Dragon Copilot for Nurses launch (announced October 2025 with ten health-system early adopters) is too new to be in the production tier yet.
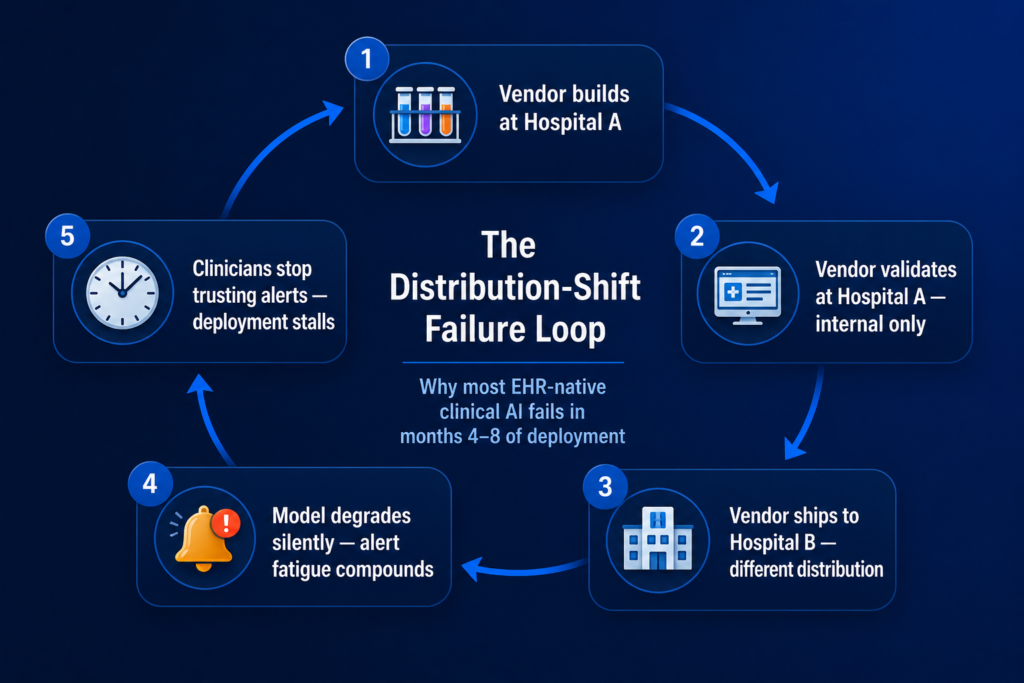
The Failure Mode Underneath: Distribution Shift the Vendor did not Test For
The Epic Sepsis Model is the canonical example of the production failure mode in hospital AI and it is worth dissecting because the same loop is operating today on most of the stalled use cases above.
The University of Michigan team published the external validation in JAMA Internal Medicine in June 2021. The findings: across 27,697 patients undergoing 38,455 hospitalizations at Michigan Medicine, the Epic Sepsis Model — already deployed at hundreds of US hospitals — predicted sepsis onset with an AUC of 0.63, substantially worse than the 0.76–0.83 the developer had reported. Sensitivity was 33%, specificity 83%, positive predictive value 12%, negative predictive value 95%. The model missed 1,709 of 2,552 sepsis cases at the threshold score of 6 — two of every three. And it generated alerts on 18% of all hospitalized patients, driving the alert-fatigue burden that everyone in clinical informatics recognizes.
The 2024 replication at Harris Health System in Houston pushed the result harder. Across 145,885 ED encounters, the Epic Sepsis Predictive Model v1.0 at a six-hour sepsis onset window posted a sensitivity of 14.7% and a positive predictive value of 7.6%. The model worked worse on a different patient population than it had at Michigan, which had worked worse than the developer had originally reported.
The structural cause is distribution shift. The model was trained at one institution on one EHR configuration with one set of labeling practices, lab vendors, scanner manufacturers, and patient demographics, and it was deployed at hospitals with different versions of every one of those variables. The recent npj Digital Medicine cross-cohort study (HiRID, MIMIC-IV, eICU; 216,536 ICU stays) confirmed the pattern empirically — sepsis prediction models trained on ICU data fail to generalize under external validation because of distribution shift, and standard transfer learning recovers only part of the performance gap.
This is the structural reason the three production categories above work and the others do not. Imaging triage works because DICOM is reasonably standardized and the FDA pathway forces external validation. Ambient documentation works because the human is the verifier. RCM works because the payer labels every prediction in days. Everything else either trains on operational artifacts that vary across sites, or ships without the validation discipline to catch the drift before it lands in clinical workflow.
The Epic Sepsis Model worked at Epic. It did not work at Michigan. It worked even less at Harris Health. The model is not the unit of validation — the deployment site is. Every hospital is a different distribution, and the AI you bought was probably trained somewhere else.
The 3-Track Acute-Care AI Production Bar
After working through the deployment evidence and the validation literature, the pattern is consistent
enough to be a framework. Every category in the production tier passes all four tests below. Every
category in the stalled tier fails at least two. Apply this gate before you fund anything.
Distribution stability
Is the input distribution stable enough across hospitals that the model does not silently degrade across
sites? DICOM imaging, payer adjudication outcomes, and clinician-spoken English are reasonably stable.
EHR vital-sign streams, lab-result conventions, and physician documentation patterns are not. Models
trained over operationally-encoded variables drift the moment they leave the training site. The Epic Sepsis
Model failed Test 1 explicitly.
Verifier presence
Is there a human in the loop who verifies the AI output before it reaches the patient or the payer? Ambient
documentation has a verifier — every clinician reviews the note. Imaging triage has a verifier — every flag
is a radiologist check. RCM has a payer-of-record adjudicating in days. EHR-native sepsis prediction does
not have a meaningful verifier in time — the alert fires faster than a clinician can adjudicate, which is
precisely how alert fatigue compounds.
Integration depth
Does the AI’s output appear inside Epic, the existing PACS, or the existing RCM stack? Or does it sit in a
standalone dashboard? The use cases in production all sit inside the daily clinical or financial system. The
use cases that stall almost always sit in something the team has to log into separately. This test is
operationally identical to the integration-depth test that took the AEC AI bifurcation into the same shape —
and per IDC research, integration debt is the dominant root cause of the 88% pilot-to-production failure
rate in enterprise AI generally.
External validation discipline
Has the model been externally validated at a hospital that did not participate in its training? Is the
validation peer-reviewed? Per the recent AI-in-radiology survey, 64% of commercially available AI products
in the category have no peer-reviewed evidence behind them — and only a small fraction demonstrate
clinical impact beyond diagnostic accuracy. A vendor pitch is not external validation. An FDA 510(k) pivotal
study is. A JAMA, NEJM, Lancet Digital Health, or npj Digital Medicine paper is.
Use cases that fail two or more tests stay in pilot. Use cases that pass all four ship to production.
Apply the bar before signing the SOW, not after the pilot has burned six months.
Build vs Buy vs Partner — by Health System Size and AI Maturity
For the three production categories above, off-the-shelf SaaS is usually the right starting move. Build or partner-led only when you have proprietary data, proprietary process IP, or a use case the SaaS market has not yet reached.
What Mitesh has seen Across 70+ Enterprise AI Deployments
“Across the AI systems we have shipped — including HIPAA-compliant document AI pipelines
moving 50,000-plus documents per month at 47 formats and 80% manual-review reduction, plus
computer vision running on NVIDIA Jetson Orin at sub-50ms inference for production
manufacturing — the validation step that catches site-specific distribution shift takes two to three
times the engineering time of the model itself. That is the part nobody benchmarks at conference
demos. It is also where most clinical AI pilots quietly die in months four through eight. Get the
validation protocol right and the deployment ships. Get it wrong and no amount of model retraining
will recover the project.” — Mitesh Patel, NVIDIA Certified AI Architect, Founder & Director, Brainy
Neurals
If your hospital has approved three clinical AI pilots in 18 months without one
production deployment, the issue is not AI maturity. It is that nobody on the team is accountable for
site-specific validation. The model that works at Mayo will not work at your hospital until someone
proves it does — and that proof is a peer-reviewed external validation, not a vendor case study.
A confession about how AI specifications actually fail in healthcare
We have rewritten 40+ AI specifications mid-project at this point across healthcare, BFSI,
manufacturing, and pharma. The pattern in healthcare is always identical: the spec was written by
someone who had not operated through the site-specific failure mode the system would hit in
production. The model worked. The Epic integration worked. The HIPAA posture was clean. And
then the alert fatigue rose past the threshold where the on-call hospitalist stopped trusting the flag,
and the deployment quietly went into the same drawer as the last three pilots. The fix is rarely a
better model — it is a better validation contract that requires the vendor to prove the model works
at your hospital, on your patient mix, before go-live.
When this Audit does not Apply — Failure Modes Worth Naming
Critical access hospitals and rural facilities
Per AHA/ONC data, rural hospitals report 56% predictive AI adoption versus 81% urban; critical access hospitals report 50% versus 80% non-CAH. The economics, EHR vendor mix, and integration paths are different enough that the production-tier playbook above ports incompletely. Off-the-shelf SaaS economics often do not work at sub-100-bed scale.
Hospitals running non-Epic EHRs
The Microsoft Dragon Copilot and Abridge production paths are deepest at Epic. Oracle Health, MEDITECH, and Altera Digital Health hospitals have viable ambient documentation paths but the integration-depth test (Test 3) takes more engineering time and the named-adopter list is shorter.
Federal facilities (VA, IHS, military health)
The deployment paths are gated by federal procurement, which moves on a different timeline than commercial health systems. The production-tier vendor list above is not a procurement-ready vendor list inside the federal stack.
Joint ventures and academic-affiliated clinical trials
When the data crosses an institutional boundary, the data-rights and IRB layers redefine the validation contract. The site-specific validation test (Test 4) becomes more complicated and more important.
What the Numbers Actually Look Like
97-98%
Sensitivity / specificity — Aidoc CARE foundation model, FDA-reviewed pivotal study (January 2026)
13M
Patient encounters in a single quarter — Microsoft Dragon Copilot, FY2025 Q4
100K+ hrs
Saved across 1,000+ physicians — Mercy on Microsoft Dragon Copilot
$30M
Gross yield increase — Nebraska Methodist on AKASA claim-status automation
AUC 0.63
Epic Sepsis Model external validation vs developer-claimed 0.76–0.83; 67% of cases missed (JAMA IM, 2021)
1 of 3,000+
Respondents using agentic AI in production — KLAS Healthcare AI Update, December 2025
Sources: FDA 510(k) clearance; Microsoft FY2025 earnings; Mercy deployment data; AKASA/Nebraska Methodist; JAMA Internal Medicine; KLAS Dec 2025. Verify at source before quoting in a board deck.
Frequently Asked Questions
What this Means for Your 2026 AI Roadmap
If you run a US health system above 500 beds and you have an AI budget for 2026, the audit above gives you three concrete moves.
Production-Ready Today
- Ambient clinical documentation (Microsoft Dragon Copilot, Abridge)
- Imaging triage (Aidoc, Viz.ai across relevant clinical lines)
- Revenue-cycle denials and coding (AKASA, Solventum, Epic-native agents)
2027 Production Candidates
- Ambient nursing documentation (Dragon Copilot for Nurses, October 2025)
- Real-time prior authorization (Highmark/Abridge collaboration)
- Generative chart summarization where verifier not yet in loop
Skip Until 2028+
Not Production-Budget Ready
- Fully agentic clinical AI that bypasses a clinician verifier
- Autonomous diagnosis
- Generative clinical decision support without external validation
The pattern across the hospitals that have moved fastest — UPMC, Northwell, Duke, Mayo, Johns Hopkins, UNC, Cleveland Clinic, Mercy, Yale New Haven, Cedars-Sinai — is that they did not chase the most clinically ambitious demos. They picked the categories where the four-test bar was passable today and shipped those first.
Before You Fund Another Clinical AI Pilot in 2026, Run It Through The 3-Track Production Bar.
Get the AI Readiness Assessment — 25 questions to map where your hospital sits on the four-test bar, with a personalized scorecard and the three highest-leverage moves for your size and EHR stack.