
Edge AI Development Services — Real-Time Intelligence Where Cloud Cannot Reach
We are an edge AI development company that deploys production AI models on embedded devices — NVIDIA Jetson, Qualcomm SNPE, Intel OpenVINO, and custom edge hardware — delivering real-time inference at the point of action. Our edge AI solutions process camera feeds, sensor data, and audio streams on-device with zero cloud dependency, sub-30ms latency, and complete data sovereignty. From embedded AI development for industrial inspection to on-device AI development for construction safety, fleet management, and medical devices — we optimize, deploy, and manage AI at the edge where milliseconds and milliwatts matter.

- 70 + AI Projects Delivered
- 8 + Years Pure AI
- NVIDIA Certified AI Architect
- ISO 27001 Certified
- NVIDIA Inception Partner
- Upwork Top Rated Plus
Trusted by teams across USA, Europe & Asia






- Market Context
Why Edge AI — The Physics of Real-Time Decisions
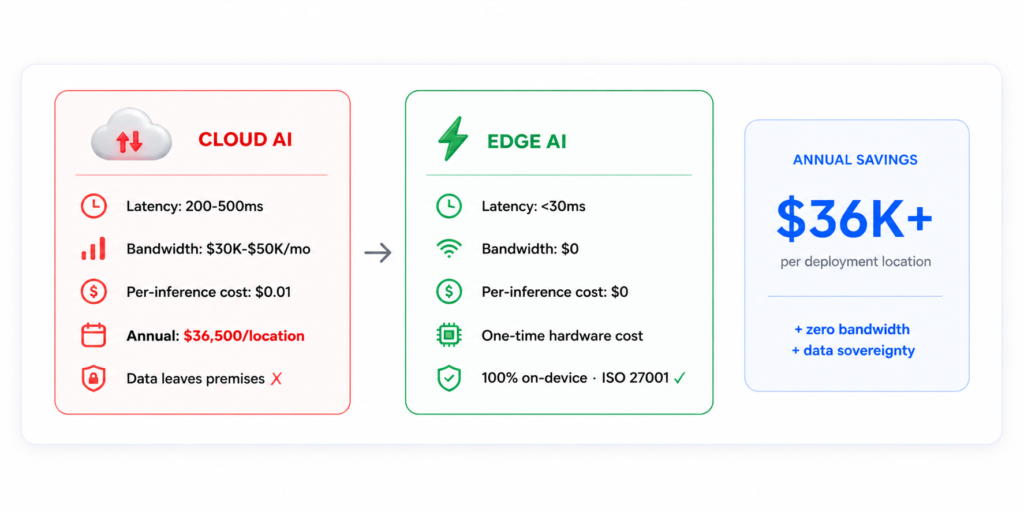
Cloud AI requires three things edge environments cannot guarantee: reliable network connectivity (a construction site, a mining operation, a shipping vessel, a rural manufacturing plant), acceptable round-trip latency (200-500ms cloud inference is physically too slow when a conveyor belt runs at 2 meters per second or a forklift approaches a pedestrian at 8 km/h), and acceptable bandwidth cost (streaming 100 cameras at 1080p to the cloud requires 15+ Gbps sustained upload, costing $30,000-$50,000 per month in bandwidth alone — before any compute charges). Edge AI eliminates all three constraints by running inference directly on hardware located at the point of action.
Edge deployment also eliminates recurring cloud inference costs: once the hardware is deployed and the model is optimized, your AI runs at zero marginal cost per inference. A cloud-deployed model costing $0.01 per inference at 10,000 inferences per day costs $36,500 per year per deployment location. An edge device running the same model costs the hardware once and electricity thereafter.
Brainy Neurals was founded on edge AI. Our very first project in 2018 was a multi-stream video processing pipeline running on NVIDIA Jetson using DeepStream and YOLOv2. Eight years later, our edge AI capabilities span every major embedded AI development platform: NVIDIA Jetson (Nano, Orin, AGX, and the new Jetson T4000 with Blackwell architecture), Qualcomm SNPE SDK for mobile and IoT, Intel OpenVINO for x86 industrial PCs, Rockwell chipsets for industrial automation, and Kneron NPUs for ultra-low-power deployments. Our founder Mitesh Patel is an NVIDIA Certified AI Architect who has personally deployed production edge systems processing 30+ FPS on NVIDIA Jetson Orin with multiple concurrent detection models — measured performance from systems operating 24/7 in industrial environments.
- Hardware Expertise
Edge AI Hardware Platforms We Deploy On
| Platform | Performance | Best For | Cost Range | Software Stack |
|---|---|---|---|---|
| NVIDIA Jetson Orin Nano | 40 TOPS, 7–15W | Cost-sensitive single-camera: retail analytics, simple inspection, access control | $199–$299 | JetPack, TensorRT, DeepStream |
| NVIDIA Jetson Orin NX | 70–100 TOPS, 10–25W | Multi-camera (2–4), moderate-complexity detection + tracking | $399–$599 | JetPack, TensorRT, DeepStream |
| NVIDIA Jetson AGX Orin | 200–275 TOPS, 15–60W | High-throughput multi-camera (8–16 streams), complex multi-model pipelines, robotics | $1,099–$1,999 | Full JetPack, Isaac SDK |
| NVIDIA Jetson T4000 NEW | 1200 FP4 TFLOPs, 64GB, Blackwell | Edge LLMs, multimodal AI, humanoid robotics, autonomous systems | Contact NVIDIA | JetPack 7.1, TensorRT Edge-LLM |
| Qualcomm SNPE Devices | Neural Processing Engine | Mobile AI, wearables, IoT sensors, drone-based inference, battery-powered | Varies | SNPE SDK, ONNX → DLC |
| Intel OpenVINO on x86 | CPU/GPU/VPU optimized | Existing x86 industrial PCs, legacy hardware retrofit with AI | Existing HW | OpenVINO toolkit, IR format |
| Rockwell Automation | Industrial-grade PLC | Inline inspection in existing Rockwell automation lines, PLC-integrated AI | Industrial | Custom ControlLogix integration |
| Kneron NPU | Ultra-low-power NPU | Battery-powered edge, always-on sensing, cost-sensitive IoT at scale | $10–$50/unit | Kneron SDK, ONNX conversion |
- What We Build
AI Inference Optimization — Making Models Run Fast on Small Hardware
The gap between a model that works in the cloud and a model that runs at production speed on edge hardware is enormous. A YOLO v8 model running at 120 FPS on an NVIDIA A100 may run at 3 FPS on a Jetson Orin Nano without optimization. Our AI inference optimization services bridge this gap.
TensorRT Optimization Services
TensorRT optimization services are the core of our edge deployment capability. NVIDIA TensorRT converts trained models from PyTorch, TensorFlow, or ONNX into optimized inference engines. Our pipeline includes precision calibration — FP32 to FP16 for 2x speedup with negligible accuracy loss, or INT8 for 3-4x speedup with calibrated accuracy validation. We perform layer and tensor fusion, dynamic shape optimization, and multi-stream inference — processing multiple camera feeds in a single GPU context with shared model weights. Our production Jetson deployments typically achieve 3-10x speedup with less than 1% accuracy loss.

Model Compression & Architecture Optimization
We reduce model size through structural techniques: pruning (30-70% weight reduction), knowledge distillation (85-95% teacher accuracy at 5-10x smaller), quantization-aware training for INT8-ready models, and neural architecture search optimized for your target hardware. For YOLO variants, we use anchor-free detection heads; for transformers, attention pruning and token reduction.
Multi-Platform AI Model Optimization Across 5 Frameworks
Our AI model optimization edge services span every major framework: TensorRT for NVIDIA Jetson, Intel OpenVINO development for Intel CPUs/GPUs/VPUs, Qualcomm SNPE AI development for Snapdragon-powered devices, ONNX Runtime for cross-platform deployment, and TensorFlow Lite for microcontrollers. We maintain optimization pipelines for all five, enabling multi-platform edge AI deployment services across your fleet.
- Applications
Edge AI Applications We Build
Edge Computer Vision & Real-Time Video Analytics
We deploy NVIDIA DeepStream-based pipelines handling multiple camera streams on a single Jetson, with TensorRT-optimized models running detection, tracking, and classification in parallel. Applications include industrial visual inspection (200+ units/hour, sub-50ms), construction safety (PPE detection across 16 cameras on one Jetson AGX), traffic management (ANPR at highway speed), retail analytics, and warehouse safety. Our edge video analytics connect to our Intelligent NVR for natural language video search.

Edge Sensor Fusion — Cameras, Depth, LiDAR, GPS
Our embedded AI development spans multi-sensor fusion: Intel RealSense depth cameras (D400/L500), Stereolabs ZED 2i stereo cameras for outdoor depth to 20m, Ouster LiDAR (128-channel) for 3D point clouds, IMU/GPS for geo-referenced detection, and industrial sensors for predictive maintenance. All processing on-device — depth maps, point clouds, GPS data synchronized in real-time on edge hardware.
Edge LLM & On-Device Language Intelligence
With the new Jetson T4000 (Blackwell, 64GB) and TensorRT Edge-LLM SDK, running LLMs at the edge is production-viable. We build on-device AI systems: voice-controlled equipment interfaces, document processing in disconnected environments (mining, offshore, military), and edge-based anomaly narration where vision models detect events and local LLMs generate human-readable incident descriptions — all without cloud connectivity.

Production Edge Infrastructure — Thermal, Power, Reliability
Our edge AI deployment services include: thermal management (Jetson throttles at 85°C, we validate for your ambient temperature), power management (9-36V DC, battery/solar backup), ruggedized enclosures (IP65/IP67, MIL-STD-810G vibration, -40°C to +85°C), OTA model updates without site visits, and remote fleet monitoring dashboards tracking device health, GPU temperature, inference latency, and accuracy across your entire edge fleet.
Need AI that runs where your cameras are — not in a data center? Book a free 30-minute edge AI assessment with our NVIDIA Certified AI Architect.
- Industries
Industries Where Our Edge AI Delivers ROI
Strongest Domain
Inline quality inspection at production speed, equipment monitoring with vibration/thermal sensor fusion, worker safety (PPE, exclusion zones), production counting. All on-device — no factory floor data leaves the premises.
Multi-camera safety monitoring, PPE detection, exclusion zones, fall hazard detection on weather-resistant edge devices. Drone-based inspection with on-device defect detection. IP65+ enclosures, solar/battery power for remote sites.
Transportation & Fleet Management
Vehicle-mounted driver monitoring (drowsiness, distraction, phone), collision warning, lane departure. Intersection traffic monitoring with ANPR. Railway inspection at 60+ km/h. All processing on-device for vehicles with intermittent connectivity.
AI-powered diagnostic devices with on-device inference (FDA 510(k) pathway). Patient monitoring. Pharmaceutical inspection. HIPAA compliance, data isolation. Edge processing ensures patient data never leaves the clinical environment.
In-store analytics (footfall, heat maps, queue, shelf monitoring) on compact edge devices. Smart buildings with occupancy detection and energy optimization. All processing local — GDPR/CCPA-compliant analytics from day one.
- Our Process
How We Deliver Edge AI Projects
Every edge AI engagement follows our production-proven methodology — designed to get you from concept to deployed edge system in the shortest path with the lowest risk.
Ongoing: Edge Fleet Operations
Remote monitoring of device health across your edge fleet. OTA model updates without site visits. Seasonal model retraining (adapting to changing light conditions). Hardware health monitoring with proactive maintenance alerts (GPU temperature trends, storage utilization, memory health). Your edge AI fleet gets smarter and more reliable every month.
Ready to deploy AI where cloud cannot reach?
- Delivered Results
Edge AI Projects We Have Delivered
Manufacturing
Tire Manufacturing — 99.2% Defect Detection on Jetson AGX Orin
Real-time surface defect detection at a tire manufacturing facility. YOLO-based model optimized with TensorRT FP16 on NVIDIA Jetson AGX Orin processes 200+ tires/hour. Custom lighting rig (structured light + dark-field) for rubber surface. Reject decisions in under 50ms. Thermal management validated for 24/7 at 35°C ambient.
Manual QC
99.2%
Detection accuracy
Construction
Construction Safety — 16-Camera PPE Detection on Single Jetson
Multi-camera PPE detection and exclusion zone monitoring across active construction sites. Single Jetson AGX Orin processes 16 camera feeds via DeepStream multi-stream pipeline. Detects missing hard hats, vests, boots, unauthorized zone entries. IP65-rated enclosure with PoE cameras. Graduated alert escalation: dashboard → mobile → PA system.
Before
60%
Violation reduction
Transportation
Railway Inspection — Automated Track Defect Detection at 60+ km/h
Vehicle-mounted CV system detecting rail surface defects, missing fasteners, clearance violations, and track geometry deviations at 60+ km/h. Ouster LiDAR for millimeter-precision rail profile measurement. Intel RealSense for close-range fastener inspection. GPS-tagged defect mapping creates geo-referenced maintenance priority maps. MIL-STD-810G vibration rated.
Manual
60+
km/h inspection speed
Traffic
Traffic Intelligence — 97% Accuracy Across All Weather Conditions
Vehicle detection, classification, and ANPR at highway intersections. Ruggedized roadside hardware rated -40°C to +85°C with IP67 protection. 97%+ accuracy across day, night, rain, fog, snow, and direct sun glare. IR-illuminated nighttime plate capture at 150+ km/h. Battery backup for uninterrupted operation during power outages.
Generic
97%
All-condition accuracy
Logistics
Depth Sensing — Volumetric Measurement for Logistics at ±1cm
3D volumetric measurement using Stereolabs ZED 2i stereo cameras on Jetson Orin for automated package dimensioning. Measures length, width, height on conveyor belts in real-time with ±1cm accuracy, feeding WMS for shipping cost calculation and truck load optimization. Processing 120+ packages per hour.
Manual review
120+
Packages/hour
Edge AI Capabilities That Ship to Production
- Honest Comparison
Cloud AI vs. Off-the-Shelf Edge vs. Brainy Neurals
Enterprise teams evaluating edge AI have three deployment approaches. Here is an honest comparison.
- Why Us
Why Enterprise Teams Choose Brainy Neurals for Edge AI

Founded on Edge AI — Our Deepest Technical Moat
Brainy Neurals’ first project in 2018 was an NVIDIA DeepStream + YOLOv2 pipeline on NVIDIA Jetson. Edge AI is not a capability we added — it is the engineering discipline this company was built on. When your Jetson drops frames at 2 AM because of a GStreamer pipeline stall, when your edge device thermal-throttles because the thermal paste was insufficient, when your TensorRT INT8 quantization produces 5% accuracy loss on one specific defect type — we have diagnosed and fixed these exact failures across 70+ production deployments over 8 years.

NVIDIA Certified AI Architect — Founder-Led
Founded and led by Mitesh Patel, an NVIDIA Certified AI Architect with production deployment experience on every Jetson generation from Nano to AGX Orin. Mitesh has personally built inference pipelines using Qualcomm SNPE SDK, integrated Intel RealSense depth cameras and Stereolabs ZED 2i, processed Ouster LiDAR point clouds, and optimized models with TensorRT, ONNX Runtime, and Intel OpenVINO. His Upwork Top Rated Plus profile provides third-party verification.

8 Hardware Platforms — Not Just NVIDIA
Our hardware comparison table lists 8 platforms — including Jetson T4000 (Blackwell), Qualcomm SNPE, Intel OpenVINO, Rockwell, and Kneron — because we have deployed production systems on all of them. When your use case requires a $10 Kneron NPU for battery-powered sensing or an Intel OpenVINO retrofit on existing x86 PCs, we do not force you onto Jetson. We match hardware to your constraints.

Backed by AWS, Microsoft & NVIDIA
Simultaneously in AWS Activate, Microsoft for Startups, and NVIDIA Inception. For edge AI this matters: most production deployments are hybrid — edge handles real-time inference, cloud handles retraining, fleet management, and analytics. We deploy edge-cloud architectures on AWS, Azure, or NVIDIA infrastructure optimized for your existing environment.

ISO 27001 + Edge Data Sovereignty
Edge AI processes the most sensitive visual and sensor data — factory footage, medical images, defense applications. Our ISO 27001 certification ensures information security at every stage. Edge-first architecture inherently protects data sovereignty: all processing on-device, encrypted local storage, secure boot, and tamper detection for high-security environments.
US Market Credibility
Leadership team with direct experience in large-scale, highly regulated procurement environments. We operate across EST and GMT hours with daily standups, weekly demos, and under 4-hour response times. Full IP ownership on every project.”
Download: Edge AI Hardware Selection Guide
The framework we use for 70+ deployments — NVIDIA Jetson vs. Qualcomm vs. Intel decision tree, power budgets, thermal envelopes, cost-per-inference analysis, and ruggedization requirements. Free, no strings.
- FAQ
Frequently Asked Questions About RAG Development
What is edge AI and how is it different from cloud AI?
Edge AI runs artificial intelligence models directly on local hardware devices — such as NVIDIA Jetson, industrial PCs, or embedded processors — at the point where data is generated. Cloud AI sends data to remote servers for processing. Edge AI provides sub-30ms inference latency (compared to 200-500ms for cloud), eliminates network dependency, provides complete data sovereignty, and eliminates per-inference cloud costs. An edge AI development company like Brainy Neurals designs, optimizes, and deploys custom AI models on edge hardware — handling TensorRT optimization, thermal management, multi-stream inference, and production reliability engineering that cloud deployments do not require.
Which edge AI hardware should I choose?
Hardware selection depends on your specific requirements. NVIDIA Jetson Orin Nano ($199-$299) suits cost-sensitive single-camera deployments. Jetson AGX Orin ($1,099-$1,999) handles 8-16 camera streams with complex multi-model inference. Qualcomm SNPE devices excel at battery-powered mobile and IoT. Intel OpenVINO runs on existing x86 industrial PCs. Rockwell and Kneron serve specialized industrial and ultra-low-power applications. Brainy Neurals evaluates your inference complexity, camera count, power budget, thermal constraints, and cost target to recommend the optimal platform — including hybrid approaches using different hardware at different locations.
How do you optimize AI models for edge deployment?
We optimize through multiple techniques: TensorRT quantization (FP16 for 2x speedup, INT8 for 3-4x speedup), model pruning (30-70% weight reduction), knowledge distillation, layer and tensor fusion, multi-stream batched inference, and hardware-specific compilation (TensorRT for NVIDIA, OpenVINO for Intel, SNPE for Qualcomm). Our production NVIDIA Jetson development services typically achieve 3-10x speedup with less than 1% accuracy loss.
Can you add AI to our existing camera infrastructure?
Yes. Our edge AI solutions integrate with any existing IP cameras via RTSP and ONVIF protocols. We add edge processing hardware (NVIDIA Jetson or GPU server) to your existing camera network — no camera replacement required. For legacy analog cameras, we use IP encoders. We also integrate with existing VMS platforms (Milestone, Genetec, Exacq) and enterprise systems through standard APIs.
How do you handle edge devices in harsh environments?
We engineer production edge systems for real-world conditions: ruggedized enclosures rated IP65/IP67 for dust and water protection, MIL-STD-810G vibration resistance for vehicle-mounted deployments, wide temperature operation (-40°C to +85°C), custom thermal management (Jetson thermal-throttles at 85°C), power management with 9-36V DC and battery backup, and tamper-resistant designs. We have deployed edge AI systems on construction sites, highway intersections, rail inspection vehicles, factory floors, and logistics warehouses.
- Explore More
Related Services & Pages
Computer Vision Development
Every edge AI system we deploy runs computer vision models optimized for edge hardware.
Video Analytics & Intelligent Surveillance
Our edge-deployed video analytics power the Intelligent NVR and real-time safety monitoring.
Robotics & Hardware Automation
Edge AI powers the perception layer for robotic systems and autonomous equipment.
AI in Manufacturing
Edge AI for inline quality inspection, worker safety, and production monitoring.
AI in Construction
Ruggedized edge AI for PPE detection, exclusion zones, and progress tracking.
AI POC & Pilot Development
Validate your edge AI concept in 4-6 weeks with a working prototype on your target hardware.
- Let’s Build AI for Your Everyday Challenges
Among the Top 3% of Global AI Professionals.
50+
9+
- We respond within 24 hours
Or email: hello@brainyneurals.com