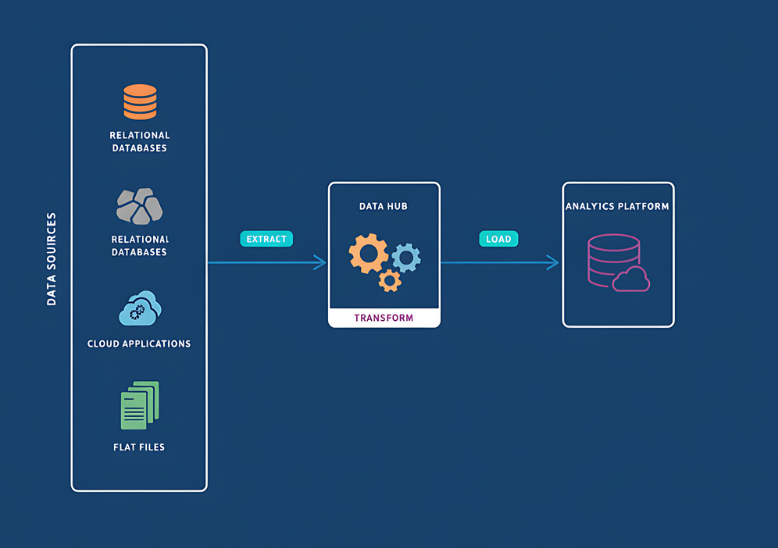
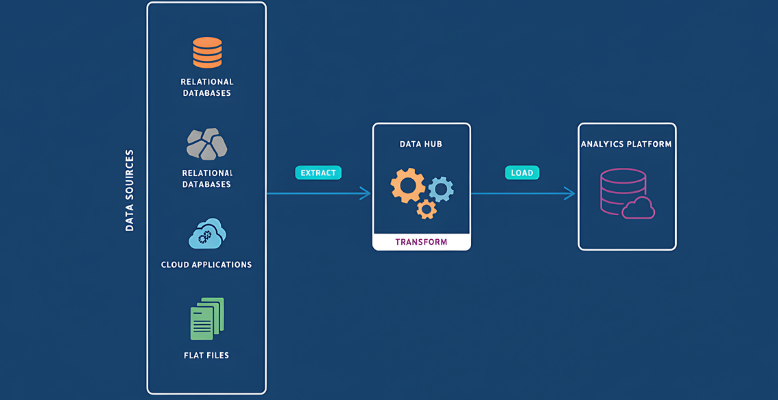
Data Pipeline Design
We build scalable, fault-tolerant pipelines that collect, process, and integrate data from multiple sources in real time. Our architectures support both batch and streaming workflows designed to deliver consistency, reliability, and speed at scale.
Data Quality & Transformation
Our systems clean, normalize, and structure raw data for usability and accuracy. With automated validation and transformation, we ensure your data remains trustworthy and analytics-ready for all business and AI applications.
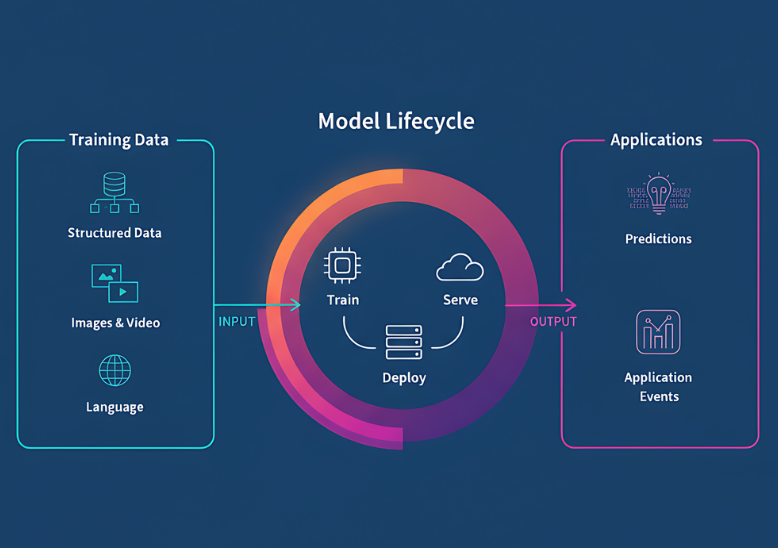
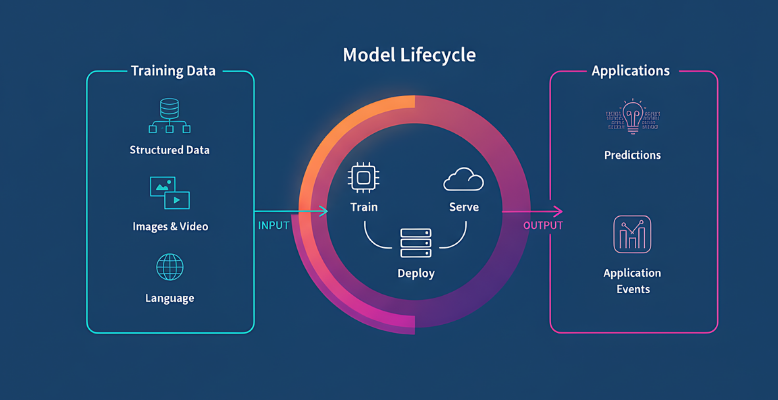
AI-Ready Data
We bridge AI in Data Engineering by preparing optimized datasets tailored for machine learning models. Every pipeline is tuned to improve training speed, inference accuracy, and data accessibility for seamless AI adoption.

Tool & Workflow Integration
We connect your data ecosystem with business tools like Slack, Asana, CRMs, and reporting dashboards. This integration ensures that data-driven insights reach your teams instantly streamlining collaboration and decision-making.

Accelerating product research with integrated data automation across Asana, SEMrush, and Google Sheets.
- Fetches market and keyword data automatically
- Generates analysis sheets and financial metrics
- Updates project progress in real time
Result
90% ↓
Research time
100%
Accuracy in calculations

Cutting clinical trial setup from months to days with AI-based document processing.
- Extracts forms and fields from protocols
- Maps data to CDASH and MedDRA standards
- Generates complete eCRF specifications
Result
12 weeks
➜ 3–4 days
100%
Standards compliance

Creating a virtual replica of container logistics to optimize flow, reduce delays, and improve planning efficiency.
- Real-time simulation of vessel, crane, and container movement
- Data-driven analysis for bottleneck detection and route optimization
- Scalable framework for testing multiple operational strategies
Result
60% ↓
Planning and testing time
95%
Accuracy in operational forecasting

Turning real-time news and social sentiment into actionable market insights.
- Gathers trending topics from media and social platforms
- Analyzes tone and investor reactions
- Correlates sentiment with stock movements
Result
80% ↓
Analysis time
92%+
Sentiment accuracy



















